粒子群最佳化法(Particle Swarm Optimization)中的每個體稱稱為「粒子」(particle),是代表解空間(solution space)中的一個可能的解。每個粒子的移動除了出自本身的慣性(inertia)外,還參考個體本身最佳經驗移而產生認知學習(cognitive learning)的遷移,也參考群體整體最佳經驗做社會學習(social learning),迭代演化前進,最後收斂而得到最佳解。
PSO的濫觴乃源於自然界生物活動的觀察,模擬鳥群、魚群之覓食得群體行為(social behavior)所發展出來的演算法[1][2]。這類源自觀察生物群之個體、族群間的互動行為,是一種模擬自然生物群體系統的演算法。這類源自模擬生物群體活動來找optimal solution的方法,稱為swarm intelligence,有人更廣泛的稱為Nature Inspired Computing (NIC)。
Particle swarm optimization is a derivative-free global optimum search algorithm based on the collective intelligence of a large group of intercommunicating entities. The individual particles are simple and primitive, knowing only their own current locations and fitness values, their personal best locations, and the swarm's best location. Each particle continually adjusts its trajectory based this information, moving towards the global optimum with each iteration. The swarm as a whole displays a remarkable level of coherence and coordination despite the simplicity of its individual particles. The coordinated behavior of the swarm has been compared with that of a flock of birds or a school of fish.
一、PSO簡介
PSO為meta-heuristic search的演算法,所謂的heuristic是指以(實際搜尋)的經驗進行求解的方法;以「亂數」為基礎的搜尋技巧則稱為meta-heuristic,並以反復嘗試增進可能解品質的方式,達到問題最佳化的運算方法。
The term “metaheuristics” was first proposed by Glover on 1986. The word “metaheuristics” contains all heuristics methods that show evidence of achieving good quality solutions for the problem of interest within an acceptable time. Usually, metaheuristics offer no guarantee of obtaining the global solutions.
Metaheuristics can be classified into two classes; population-based methods and point-to-point methods. In the latter methods, the search invokes only one solution at the end of each iteration from which the search will start in the next iteration. On the other hand, the population-based methods invoke a set of many solutions at the end of each iteration. [註1]
Meta一詞可做【後設】解,通常【xx的xx】我們就稱為meta XX。如:後設認知,是指對於自己認知知覺的認知,就是:你知不知道自己知不知道的能力就為【後設認知】。
Meta-Heuristic可稱作【以實證方法求解的實證解法】。這裡的【實證、經驗、Heuristic】是一種【實證方法】。就是在求最佳解時,將所有可能解代入條件函數後比較而決定出(可以接受的,未必是絕對)的最佳解。換個方式來說,Metaheuristics 利用外層(上層、概念層)的架構來控制內層(底層、操作、實作的)的一種Heuristic解法。以Nature Inspired Computing來說,就是以自然的觀察現象,如:基因演化、魚鳥群、螞蟻群、蜜蜂群覓食等現象,做為外層的控制架構的經驗式演算法。底層的heuristic approach則為以隨機方式為主的Stochastic learning。除了NIC之外,也有以音樂協調性為啟發的harmony search 等。
關於heuristics 和 metaheuristics 之間的差別(關於What is the difference between heuristics and metaheuristics?),也有此一說:heuristics 處理問題相依的訊息,只能解決特定的問題;而metaheuristics 則設計能用來解處理較廣泛問題的模式及演算法。
You could say that a heuristic exploits problem-dependent information to find a 'good enough' solution to an specific problem, while meta-heuristics are, like design patterns, general algorithmic ideas that can be applied to a broad range of problems. 【stackflow】
粒子群最佳化屬於meta-heuristic,不必對要最佳化的問題設立任何假設,就可以在空間中搜尋很大範圍的可能解。然而,如 PSO 等的meta-heuristics方法,卻不保證一定能找到絕對的最佳解。具體而言,粒子群不使用問題的梯度資訊(gradient),這意味著 PSO不需要以問題之可微分為前提,這點截然不同於須有可微分為前提的傳統最佳化方法,如:gradient descent和 quasi-newton methods。因此,PSO具有更強大解決一般最佳化問題的能力,包括某些傳統最佳化法所無法處理的最佳化問題。
二、PSO演算法的基本概念
PSO的概念場景:假設有一群魚在池塘裡以隨機巡遊的方式搜尋著食物,這群魚所處的池塘是一個n維的解空間(solution space),也是目標函數和適配函數(fitness function)所處的定義空間。池塘中食物的大小代表解的優劣,為位置的函數並視為適配值。池塘裡最大食物為最佳解,這群魚透過參考並分享個體最佳化的訊息,逐步收斂而搜尋到最佳值的位置。
PSO的求解過程:任何一隻魚在巡游搜尋最佳解的過程中,會記下自己所經歷的最大的那塊為區域最佳值(local optimal),所有區域最佳值中的最大值為訊息分享而得知的全域最佳值(global optimal),也會被記錄下來為群體的記憶。
PSO藉由記憶訊息的分享,亦即經由與個別最佳(local best)、群體最佳(global best)的比較,來調整前進的方向,決定下一步搜尋的速度,包括下一步移動的方向和距離,迭代演進搜尋找到最優解。
下面這二張圖可以具體呈現PSO的概念,第一張圖是已知相關的「梯度資訊」(gradient information),第二張則對「梯度資訊」一無所悉,僅知道目前的狀態。PSO雖然有用適配度函數(fitness function)做為優劣的評判,但並沒有使用到「梯度資訊」。也就是說,PSO在有或無「梯度資訊」的情況下皆適用。

PSO 以一群隨機粒子(隨機解)為起始,迭代演進的過程中不斷產生往最佳解前進的「速度」而如何能知道往最佳解前進的「速度」呢?
PSO中的粒子由局部、群體的最佳經驗值的驅動牽引,在solution space中搜索。每次迭代中,粒子通過跟蹤兩個"極值"來更新自己的位置。粒子本身所經歷的最優解稱為「個體極值」pBest;整個種群目前已知的最佳解為群體極值gBest。
PSO往最佳解移動的「速度」由三項力量共同決定,其速度內涵實乃包括:方向和距離(大小)。這三項驅使個體粒子往最佳解移動的動力為:目前速度(慣性)、區域極值、群體極值

1.與區域極值的差(Spring force towards the personal best position, p, ever achieved by that individual particle)
2.與群體極值的差(Spring force towards the global best position, g, ever achieved by any particle)
3.目前的速度的慣性(A frictional force, proportional to the velocity.)
這3者共同決定新的速度如下:
Vi(t +1) = ω*Vi (t) + c1r1(pBest - Xi (t))+ c2r2(gBest - Xi (t)) (1)
然後,再算出新的解(位置) Xi (t +1) = Xi (t) +Vi (t +1) (2)
式子中,ω為慣性權重(inertia weight), c1為認知係數 (cognitive parameter),c2為社會係數(social parameter)。各自有的特定的值或設定值的方式,其對PSO效能的影響也是很多研究探討的議題。
三、PSO演算法
PSO演算法如下pseudo code所示:
For each particle
Initialize particle
END
Do
For each particle
Calculate fitness value
If the fitness value > (pBest)
then (pBest) = the fitness value
End
/* Choose the particle with the best fitness value of all the particles as the gBest*/
If (pBest)> (gBest)
then (gBest) = (pBest)
For each particle
Calculate particle velocity according equation (1)
Update particle position according equation (2)
End
While maximum iterations or minimum error criteria is not attained
四、PSO參數在實務上的設置、調控:
執行PSO演算法必須先決定 c1, c2 和 vmax的值。選取的值對PSO的收斂速度和法能夠找到最佳值有一定影響,且不同型態的問題也許會有不同的適當的值。
1.粒子數: 一般取 20~ 40. 其實對於大部分的問題10個粒子已經足夠可以取得好的結果, 不過對於比較難的問題或者特定類別的問題, 粒子數可以取到100 或 更大。
2.中止條件: 設定最大循環數或最小的誤差來結束搜尋,中止條件通常也隨問題的條件而異。
3. vmax: 最大速度,決定粒子在一個循環中最大的移動距離,通常設定為粒子的範圍寬度,例如上面的例子裡,粒子 (x1, x2, x3) x1 屬於 [-10, 10], 那麼 vmax 的大小就是 20
在每一維粒子的速度都會被限制在一個最大速度vmax,如果某一維更新後的速度超過用戶設定的vmax,那麼這一維的速度就被限定為vmax。
4.慣性權重: ω
若ω=0, 則粒子的速度取決於個體最佳經驗和群體最佳經驗;這意味著粒子可快速更改其速度,立即從已知的最佳位置迅速改變位置到很遠的更佳位置。因此,較小的慣性權重會有侷限於局部搜索(local search)的傾向,稱為「exploitation」探索。
若設定較高的ω,則粒子速度的改變率較低,亦即它有明顯遵循其原來路徑的「慣性」,甚至在得知更佳的適配值fitness values後,仍固著於原來的位置。因此,高慣性權重有全面搜索(global search)的傾向,稱為「exploration」探索。
較大的慣性權重使PSO的使粒子有較大的運動慣性,粒子群因此具有較強的探索力 (exploration) ,傾向執行較大範圍的全面搜索 (global search) 。而較小的慣性權容易抑制粒子的運動慣性,則具備較強的局部搜索 (local search) 傾向的探勘力(exploitation)。
When the swarm size is large, a smaller inertia weight is utilized to enhance the local search capability for fast convergence rate. If the swarm size is small, a larger inertia weight is employed to improve the global search capability for finding the global optimum. For an optimization problem on multi-dimension complex solution space, a larger inertia weight is employed to strengthen the ability to escape from local optima. In case of small dimension size of solution space, a smaller inertia weight is used for reinforcing the local search capability[16].
(一)Inertia Weighting Strategy
a.常數慣性權重
b.隨時間變動的慣性權重:含與時間(代數)變數相依的變動的權重。最常用的時間變動變動模式是遞減的慣性權重(decaying inertia weight) ,文獻 [6,7]中提出一種遞減的慣性權重,目的在將搜尋初期設定為global search,而隨著時間的進行慢慢將搜尋變更成 local search的模式。而若要使用固定的慣性權重,則建議的ω值是介於[0.8, 1.2]之間。而遞減的方式有:線性遞減的慣性權重(Linear decreasing inertia weight),對數遞減的慣性權重(Logarithm decreasing inertia weight)、指數遞減的慣性權重(Exponenotial decreasing inertia weight)、S遞増的慣性權重(Sigmoid Increasing Inertia Weight)等。
線性遞減權重(inertia weight)的概念於1998 年由Shi 和 Eberhart 首先提出,為原始的PSO 演算法加入了線 性遞減權重w 這個因子,形成了當前PSO 的標準版本。增加了w 後,w的設置改善了許多應用的表現。在過去的研究實驗中w 通常被設置由0.9 線 性遞減至0.4。合適的數值設定將可以提供局部和全域一個平衡的探索(exploitation)及開發(exploration)能力,較大的 w 可使粒子具備較大的探勘(exploitation)能力,較小的w 能使粒子具備探索(exploration)能力 [15],w 的加入也使得演算法減低了每回合需小心設定Vmax 的需求[14]。
c.動態慣性權重(dynamic inertia weight),是與時間(代數)變數獨立的變動權重,如隨機或混沌慣性權重(Chaotic Inertia Weight),為不以演化代數為相依變數的變動權重。
d.適應性權重(adartive inertia weight):探測演化的狀態以獲取回饋來調控慣性權重的大小。
(二).學習因子: c1 (認知係數) 和 c2 (社會係數)一般是取介於[0, 4]之間的值,並設定c1 = c2,常用的數值是2。
儘管認知係數及社會係數對PSO的影響並不大,但選取適當的學習因子,仍是有助於獲得較好的效能。在決定慣性權重時,通常必須考慮的收斂速度和局部最佳化(alleviation of local mini)等因素。下表列出相關研究中所提出建議的PSO參數設定值,也適用於的常見的標竿基準函數,可做為PSO參數設定時的參考:
表一:PSO參數設定
|
c1 |
c2 |
ωinit |
ωfinal |
Reference |
|
2.0 |
2.0 |
1.0 |
1.0 |
[3] |
|
2.0 |
2.0 |
0.9 |
0.4 |
[7] |
|
1.4962 |
1.4962 |
0.7968 |
0.7968 |
[8] |
在[5]的研究中,探討關於收斂的理論;研究[8] 以不同組合的收斂速度為基礎提出一套決定參數的經驗程序(heuristic procedure);研究[9]指出最佳的結果出現在當限制項(constraint)等於最大速度(velocity clamping)時,也就是:vmax = xmax 時。這些都決定PSO參數時是很好的參考和依據。
一般來說,迭代演化式計算的優勢在於:可以處理節點傳遞函數不可知或沒有梯度信息的問題。但是也有其缺點,特別是在某些問題上的效能並不好。因此探討個別參數對最佳化效能的效應,為有意義和價值的研究。
常用的測試函數 (更多參考)

The movie below shows how the particle positions and velocities change as a function of iteration when using the PSO algorithm to find the maximum of a sinc function in 2D space.
Examples
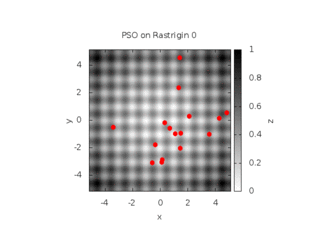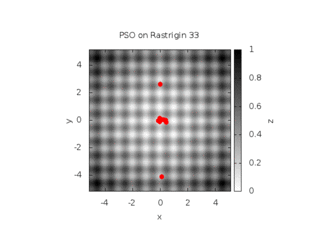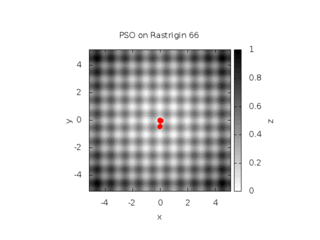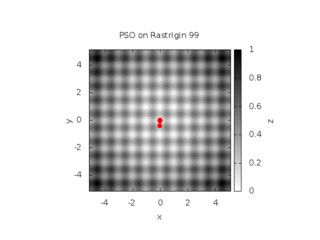
On the illustration below, you find the evolution of a swarm with a full connectivity, involving 16 particles on the 2D Rastrigin function. This function is displayed below :

We consider three conditions (see the documentation for the meaning of the parameters) :
Cognitive only with w = 0.729844, c1=1.496180, c2=0
Social only with w = 0.729844, c1=0, c2=1.496180
Both cognitive and social with w = 0.729844, c1=c2=1.496180
This leads to the behaviors shown below :
| Cognitive only | Social only |
|---|---|
 |
 |
| Both Cognitive and Social | |
 |
{kind=link}


PSO Toolbox(Matlab) Particle Swarm Optimization (PSO) Sites
Particle Swarm Optimization Research Toolbox
Constrained Particle Swarm Optimization
(PSO)Source Code Library
[ Problem: GCP & TSP & QAP & MKP & QKP | Algorithm: PSO & SCO ]
| Title | Program | Problem* | Remarks | Author |
|---|---|---|---|---|
| PSO | VB | NOP | Basic particle swarm optimizer code | Yuhui Shi |
| RMD_PSO | IDL | NOP | IDL implementation of the PSO | Rob Dimeo |
| MLOCPSOA | AMPL | NOP | PSO uses derivative information | Ismael Vaz |
| Binary PSO | C | BIN | particle swarm optimization for Binary Problem | Maurice Clerc |
| MOPSO | C | MNO | Adaptive Multi-Objective Particle Swarm Optimizer | G. T. Pulido |
| MOPSO-CD | C | MNO | Multiobjective Particle Swarm with Crowding Distance | P. C. Naval |
| Tribes | C | NOP | A parameter free particle swarm optimizer | Maurice Clerc |
| Basic PSO | Matlab | NOP | Basic particle swarm optimization source code | Yigit Karpat |
| PSO TOOLBOX | Matlab | NOP | PSO with linkage operator | D. devicharan |
| PSOt | Matlab | NOP | PSO in Trelea, Common, and Clerc types | Brian Birge |
| Hybrid PSO | Matlab | NOP | PSO hybrid with @fminsearch | A. Leontitsis |
| DEPSO | Java | NOP | Hybrid PSO with Differential Evolution (DE) [DOC] | Xiao-Feng Xie |
* For problems: NOP=Numerical Optimization; MNO=Multiobjective Numerical Optimization; TSP=Traveling Salesman Problem; BIN=Binary Problem
SwarmOps http://www.hvass-labs.org/projects/swarmops/
http://tracer.uc3m.es/tws/pso/parameters.html (Constriction factors and Parameters)
